 EN
EN FR
FR
Dear Members and Readers of Prepare For Change,
I hope this message finds you well. I am writing to update you on an unexpected and major setback we experienced recently. One week ago, our NVMe hard drive, a critical component of our server infrastructure, began showing signs of catastrophic file system corruption.
Luckily, I was on the server at the time, troubleshooting unrelated issues, when terminal warnings alerted me to the gravity of the situation. In response, I swiftly powered down the server to prevent further damage.
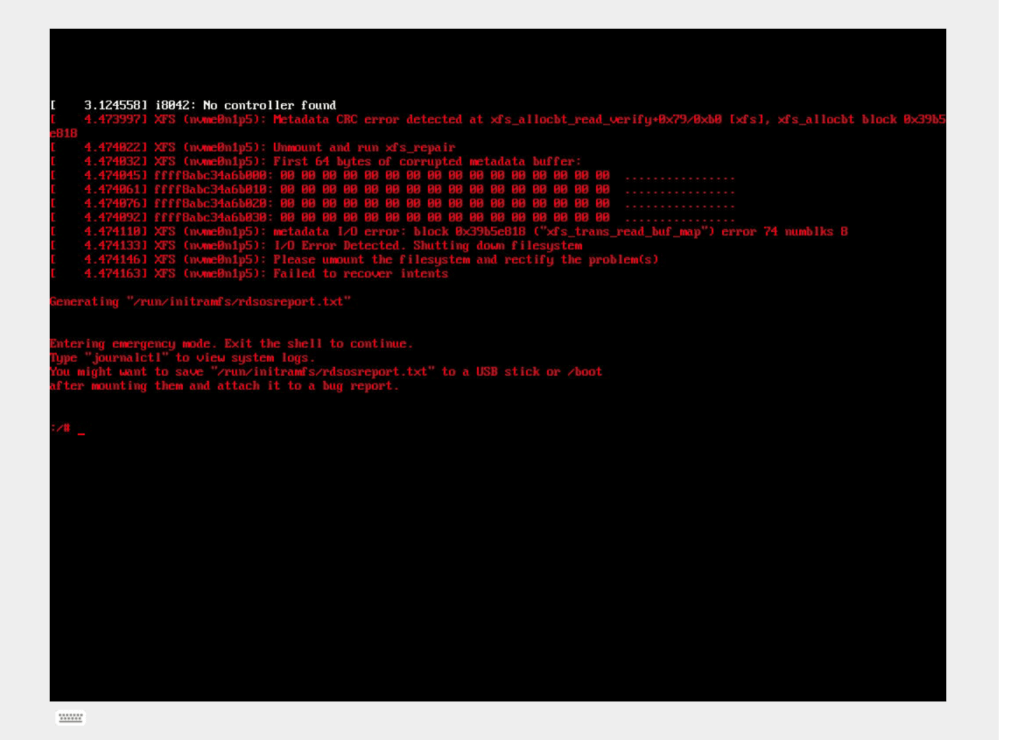
Upon inspection of our backups it was found that a glitch caused the configuration to stop working approximately one month before this event. Since no errors were showing, the lack of fresh backups was overlooked.
Therefore we had to recover the data at all costs to ensure continuity.
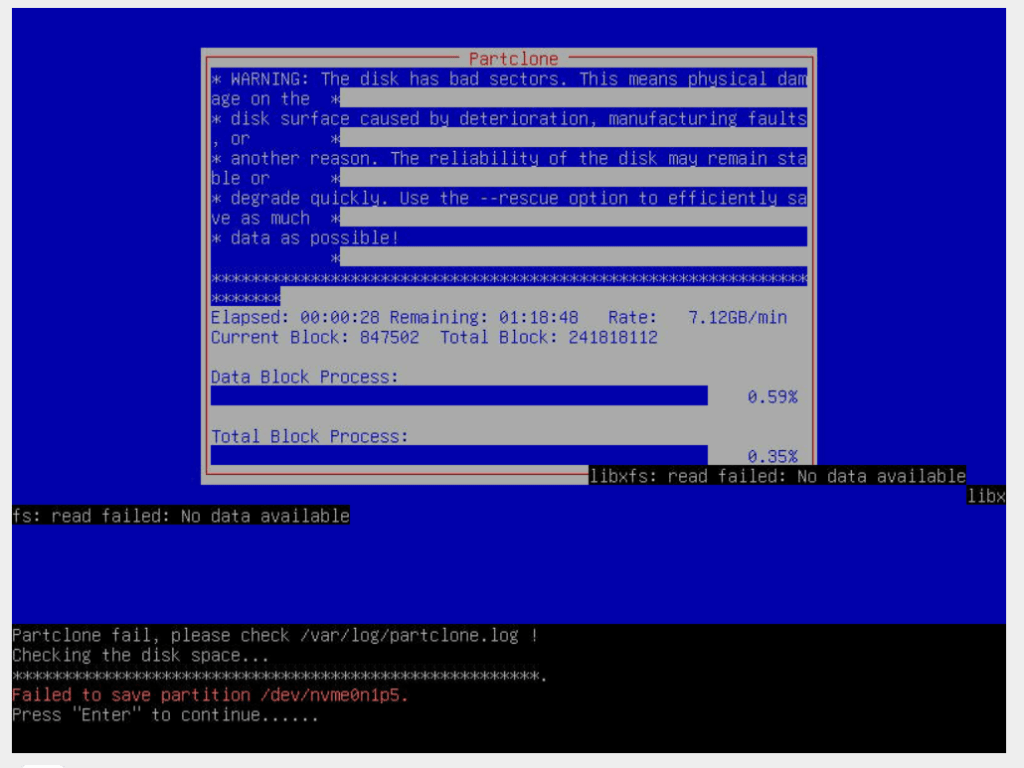
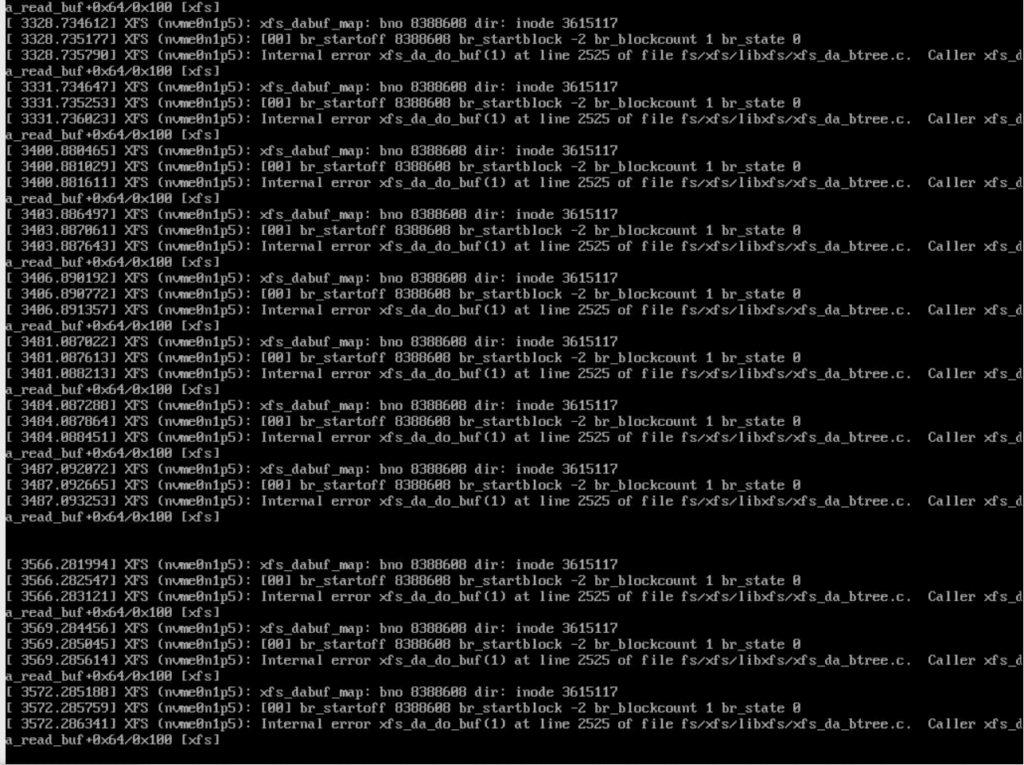
The recovery journey that followed was far from straightforward. It involved three days of crafting special block image backups, testing recovery techniques, and, due to resource limitations, having to reset and recreate the images. All this took place while the NVMe drive teetered on the edge of total failure. Even though SMART tests didn’t initially indicate a complete failure, the drive eventually did fail just prior to implementing the file system recovery.
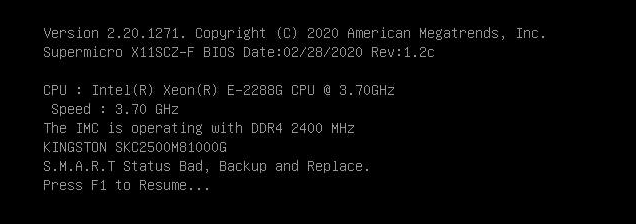
Thankfully, we managed to replace the faulty unit and re-image the new hardware. Following extensive recovery work, we were able to reboot the server. However, it was markedly unstable and suffered from lingering effects of the file system corruption. This only further exasperated the very slow but methodical process being undertaken.
For a few days it wasn’t possible to even get the database server to remain active before crashing a few seconds later. Very cautious and careful work was undertaken to ensure we lost nothing but the bare minimum.
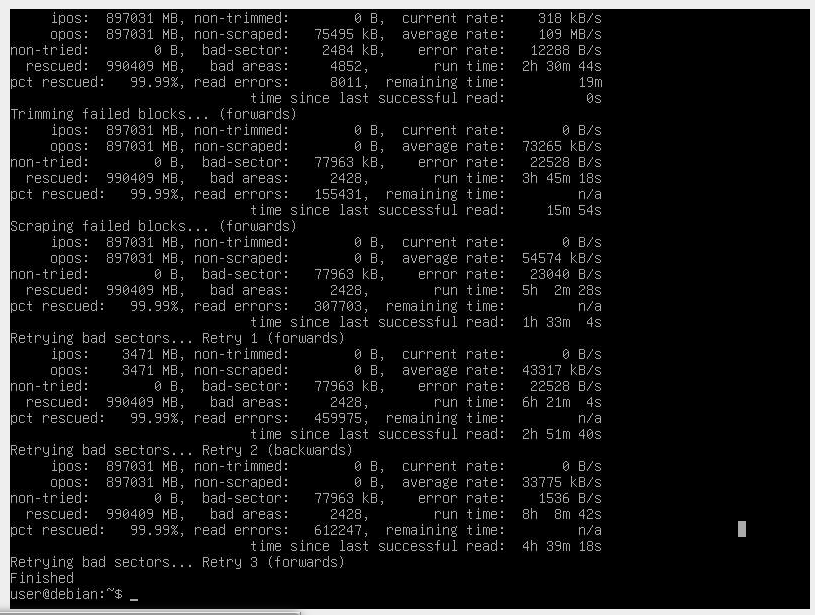
Despite these challenges, our recovery effort has been successful. We managed to recover 99.99% of the data with very marginal data loss <78MB out of 500GB+. Thankfully most of this was related to operational system files, rather than mass amounts of working data.
As part of this downtime and recovery, new infrastructure was designed and implemented on the fly. Within a week, we were able to recover, relocate, and get back on our feet from what is known in the industry as a company killer. All in all it’s took 120 hours of dedicated work to get this far.
However, our work is far from over. Additional systems still need recovery, relocation, and optimisation. Prior systems will need decommissioning and DNS records will take many days before settling into a new pace.
We are incredibly thankful for your positive wishes during this challenging time and deeply apologize for any inconvenience this may have caused. As we continue to work on bringing our teams and services back to full capacity, we kindly request your patience.
Rest assured, we are dedicated to getting our posts rolling and services fully operational as soon as possible. We appreciate your understanding and continued support.
Thank you once again, and please bear with us during this transitional period.
Kind Regards,
PFC-IT

Your Tax Free Donations Are Appreciated and Help Fund our Volunteer Website
Disclaimer: We at Prepare for Change (PFC) bring you information that is not offered by the mainstream news, and therefore may seem controversial. The opinions, views, statements, and/or information we present are not necessarily promoted, endorsed, espoused, or agreed to by Prepare for Change, its leadership Council, members, those who work with PFC, or those who read its content. However, they are hopefully provocative. Please use discernment! Use logical thinking, your own intuition and your own connection with Source, Spirit and Natural Laws to help you determine what is true and what is not. By sharing information and seeding dialogue, it is our goal to raise consciousness and awareness of higher truths to free us from enslavement of the matrix in this material realm.
Français
























{kind=link}
Wow, think your going to be happy with all new hardware, some things are unknown till one sludges thru the swamp to find the old no longer can support the need. Possibly a different bkup strategy may also share new light supporting the Forward movement. Hope you recovered. "the upper echelon usually doesn't understand torn back leather an 36+hrs straight to see their headlines stay posted.
Well Done.
least you have some sort of backup data to rely on. 3 Backup images best as possible. all you can do. with trying to get that more accurate image copy, Thats usually a test in itself.
Good luck.
Hi Tim,
Sadly our backups was a month out of date and the daily reporting on completion had given false reporting. So I didn't know. Otherwise yes I could of reverted 24 hrs and been up much sooner. We try to keep our backups well managed as we might have to pivot and move/rebuild at a moments notice given the hostility to sites that report the truth.
That being said, things happen for a reason, and this happening forced a move to new infrastructure which will eventually result in cost savings moving forward.
The new hosting and old hosting aren't exactly comparable, so there will be lots of tweaks needed to finish up the job. The new hosting architecture is better and more flexible too.
CloneZilla couldn't even handle the imaging as the drive was so corrupted, xfs was a mess. DDRescue allowed me to make the images and recover what was possible to recover.
Thanks for the best wishes.